
Prometheus监控系统(8)Alertmanager配置实例
关于Alertmanager的安装可以参考上篇文章,这里直接使用一个配置示例进行效果演示:
1、修改Prometheus主配置文件,打开与Alertmanager的通信与告警规则文件路径指定
vi /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.145.198:9093
rule_files:
- "rules/node.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.145.198:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.145.198:9100','192.168.145.199:9100']
labels:
service: node
- job_name: 'mysql'
static_configs:
- targets: ['192.168.145.198:9104']
labels:
service: db
- job_name: 'alertmanager'
static_configs:
- targets: ['192.168.145.198:9093']
2、创建告警规则文件,路径需要和rule_files中指定的一致,生产中建议配置多个告警文件,比如node.yml、db.yml,这样同类型的报警会整合在一个邮件中
vi rules/node.yml
groups:
- name: node_status
rules:
- alert: "CPU Alert low" #定义监控项1
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 30
for: 30s
labels:
severity: Low #这里定义了一个severity标签,可以根据该标签的值来进行分组
annotations:
summary: " {{ $labels.instance }} CPU使用率>30%" #可以使用变量让报警内容更直观
- alert: "CPU Alert high" #定义监控项2
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 50
for: 30s
labels:
severity: High
annotations:
summary: " {{ $labels.instance }} CPU使用率>50%"
3、修改alertmanager配置文件,配置告警收发、分组或者抑制等规则信息
vi alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:465' smtp_from: '13841276@qq.com' smtp_auth_username: '13841276' smtp_auth_password: 'mtdvgvofyfgybaxe' # 这个密码需要生成,非QQ密码 smtp_require_tls: false route: group_by: [severity] #根据规则文件中定义的severity标签进行分组 receiver: 'email' receivers: - name: 'email' email_configs: - to: '13841276@qq.com'
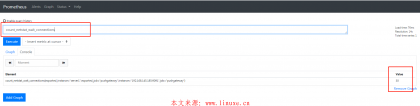
4、当规则触发后并满足持续时间时,邮箱里可以收到告警邮件,并且根据前面的group_by对邮件进行了分组发送


版权声明:本文章版权归数据库运维网(www.ywdba.cn)所有。如需引用本站内容,请注明来源及作者。



评论