
Prometheus监控系统(5)Prometheus数据类型与常用函数
一、Prometheus数据类型与函数介绍
Prometheus 提供了四种数据类型,不同的数据类型有不同的聚合函数,通过各种聚合函数的组合使用可以实现更为灵活的监控需求。由于这些聚合函数的组合使用往往需要涉及计算公式,也成为了难点所在。一些在类似Zabbix等监控系统能直接获取到的指标也需要自行使用计算公式才能实现。比如在进行CPU使用率统计时,node_exporter会抓取多种CPU指标数据,我们需要使用其中的"所有非空闲状态的CPU时间总和 / 所有状态的CPU时间总和 = CPU使用率"这样的公式才能计算出来。
一、Prometheus数据类型
1、Gauges
最简单、使用最多的指标,该指标获取的值都是随时变化且没有规律的,不能肯定它一定是增长或是减少的状态,采集回来是多少就是多少。该指标通常适用于硬盘容量、CPU内存使用率等
· predict_linear():对曲线变化速率进行计算,可以起到一定的预测作用。比如当前1个小时的磁盘可用率急剧下降,这种异常写入的情况很可能导致磁盘在未来不久就被写满,这时可以使用该函数,用当前1小时的数据去预测未来几个小时的状态,实现提前告警
predict_linear( node_filesystem_free_bytes{mountpoint="/"}[1h],4*3600 ) < 0 #根据最近1小时的数据计算未来4小时的磁盘使用情况,负数就会报警
2、Counters
计数器类型,其数据在正常状态下应该是从0开始永远递增或者是不变,单纯的Counter总数并没有直接作用,通常要借助rate、irate、topk、increase等函数来获取一个变化状态,比如监控某个指标在某个时期的增长率(增长率计算公式为 (新值 - 旧值) / 旧值 × 100%),也可以理解为在对Counter类型的数据做任何操作之前,需要先套rate()或者increase()函数
· rate() :用于计算平均增长速率,使用该函数时必须带上时间范围参数,适合用于变化较为平缓的指标,如请求总量、错误总数等
# 计算过去5分钟的HTTP请求平均速率 rate(http_requests_total[5m])
irate():比rate灵敏度更高,通过最后两个样本来计算变化率,适合监控高频变化的指标,如 CPU 使用率
# 计算CPU使用率的瞬时变化
irate(node_cpu_seconds_total{mode="idle"}[5m])
# 监控请求的瞬时速率
irate(http_requests_total[5m])· increase():获取区间向量中的第一个和最后一个样本并返回其增量
# 过去1小时内的总请求数
increase(http_requests_total[1h])
# 按服务统计过去5分钟的错误数
increase(http_errors_total{job="api"}[5m])3、Histograms
直方图类型,
4、Summary
高级指标,用于统计数据的分布情况,避免长尾问题。这个类型不太好理解,比如说统计一天的日志,大部分用户响应时间都是正常的,只有少量用户异常,如果这个时候取平均值的话,这少量用户的异常情况就会被掩盖过去,而Histograms可以分别统计出全部用户的响应时间,比如0-1秒的用户有多少、1-2秒的用户有多少(有点像Kibana)
二、PromQL 聚合函数
在 PromQL 中同样支持聚合函数,通过聚合函数可以方便快捷的对数据进行汇总、统计和分析,比如求和、求平均值、最大数值等。在使用聚合函数时和其他SQL一样,通常需要先进行分组,只不过PromQL中使用的分组语句不是GROUP BY,而是BY语句
1、PromQL 常用聚合函数
· sum():求和函数,最常用的聚合函数之一,如计算多个CPU总的负载情况
#直接使用聚合函数
sum(increase(node_cpu[1m]))
#使用by语句分组
sum(http_requests_total) by (service, environment)
· avg():平均值函数
# 计算平均 CPU 使用率 avg(node_cpu_usage) # 按数据中心计算平均值 avg by (datacenter) (node_cpu_usage)
· max()/min():最大值/最小值
# 查找最高内存使用率 max(node_memory_usage_percentage) # 按服务查找最低响应时间 min by (service) (http_response_time_seconds)
· count():进行模糊判断,比如有100台服务器在监控,想实现当CPU使用率大于80%的机器达到N台就进行报警就可以使用它
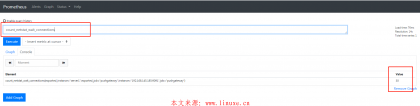
count(count_netstat_wait_connections > 200)
· topk():取排行前N的数值,比如监控了100台服务器累计320个CPU,用该函数就可以查看当前负载较高的那几个,用于报警
topk(3,count_netstat_wait_connections) #Gauge类型
topk(3,,rate(node_network_receive_bytes[20m])) #Counter类型
· over_time():over_time类函数有avg_over_time和sum_over_time等,主要区别在于over_time类函数主要用于对单条时间序列上的数据进行聚合,常用于分析单个指标的历史表现
# 计算过去1小时的平均值
avg_over_time(node_cpu_usage[1h])
# 计算多个指标的平均值
avg_over_time(node_memory_usage{instance=~".*"}[1h])2、Prometheus 函数使用示例
· 计算服务器 CPU 使用率
(1-avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) * 100
# 语句解析
# 1、node_cpu_seconds_total{mode="idle"} 通过 mode="idle" 过滤出CPU空闲时间
# 2、irate(node_cpu_seconds_total{mode="idle"}[1m]) 使用 irate 计算出1分钟内CPU空闲状态率,如果有多个CPU会逐一显示
# 3、avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) 将所有 CPU 分组聚合,然后显示平均空闲率,结果为小数形式
# 4、(1-avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) * 100 减去空闲率,算出使用率,然后将结果转换为百分比· CPU饱和度计算
node_load5 / count(node_cpu_seconds_total{mode="idle"}) by (instance, job)
# 语句解析
# node_cpu_seconds_total{mode="idle"} 记录每个 CPU 核心的空闲时间,多核CPU会有多条记录
# count(node_cpu_seconds_total{mode="idle"}) by (instance, job) 统计CPU数,并且使用instance和job分组,因为node_load5包含这2个标签
# 最后node_load5 /的值如果大于1表示系统中出现了等待的任务,CPU 饱和· HAProxy错误率计算
rate(haproxy_frontend_http_responses_total{code=~"4xx|5xx"}[5m])
/ignoring(code) group_left
rate(haproxy_frontend_http_requests_total[5m]) * 100



评论