
大数据基础(1)Hadoop背景与核心组件介绍
Hadoop在2008年已经成为Apache的顶级项目。Hadoop在国内应用非常多,比如搜索引擎、电商产品推荐、天气预报等。Hadoop的思想来自于谷歌2003年的两篇论文《The Google File System》《Google Mapreduce》,它可以构建在多台廉价的机器上,数据会自动保存多个副本,提供了高容错性,能有效存储和处理TG甚至PB级海量数据,从中获取有用数据。但是Hadoop不太适合处理低延迟的数据访问,也不支持对数据进行随机修改,这些工作还是关系型数据库更适合。
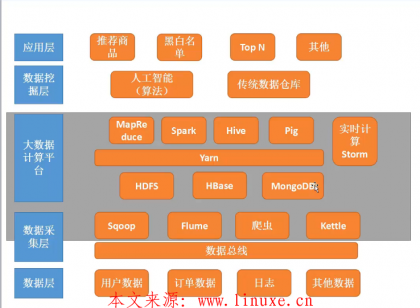
一、Hadoop核心组件介绍
· Hadoop:Hadoop集群的核心组件
· HDFS:Hadoop底层的分布式文件系统,用来存储Hadoop中的海量数据。HDFS由多个NameNode、DataNode、Secondary NameNode组成。NameNode管理整个文件系统的元数据信息;DataNode存放了文件数据,这些数据都拥有多个副本,并且可以自动检测数据副本是否缺失;Secondary NameNode则是对NameNode元数据进行监控备份。HDFS适合一次写入多次读取的场景,不支持对里面的文件进行修改,所以适合做数据分析不适合做网盘类应用
· YARN:用于管理集群中的资源分配,会根据任务需要进行内存、CPU资源的分配到合适的节点
· MapReduce:可以对海量数据进行离线计算,最终获取有价值的信息。它的计算原理就是将海量的数据打散(MAP阶段)进行计算,然后再整合(REDUCE阶段)
· Hive:通过SQL查询HDFS数据的工具,用于简化使用MapReduce进行工作的复杂度
· sqoop:Hadoop和其它关系型数据库之间实现数据抽取或导入的转换工具
· Flume:高可用、分布式的海量日志、文件采集工具,用于把大量文件或者日志存储于HDFS中
· Oozie:对Hadoop Mapreduce相关任务进行协调调度的组件,保证任务的有序进行
· Spark(开发向):专为大数据设计的计算引擎,基于内存工作,速度快,从功能上可以代替MapReduce工作,提供了包括Spark SQL、MLlib、GraphX、Spark Streaming(实时计算)等大量的库,但是发生异常后内存中的数据就会丢失
· HBase:NoSQL数据库
· ZooKeeper:分布式系统的可靠协调系统,注册中心
· Pig:大数据分析平台,为海量数据并行计算提供简易操作和编程接口
· HUE:网页管理工具
· Ambari或者CDH:安装、部署、配置Hadoop的管理系统,可以简化操作(推荐使用CDH)
· Storm:实现实时计算,类似Spark Streaming
二、大数据库三大发行版本
1、Apache:是Hadoop生态最原始的官方发行版,对于入门学习来说较好
2、Cloudera:2008年成立的Cloudera是最早将Hadoop商用的公司,发布了CDH作为Apache官方版本的改进版,让用户在部署上更容易,整体兼容性、安全性、稳定性也都有所增强,国内用户数相对较多
3、Hortonworks:发布了国内大数据发行版ambari,用户相比Cloudera要少一点,文档较好

评论